DATAGEN: Data Generation for the Social Network Benchmark
Tags:
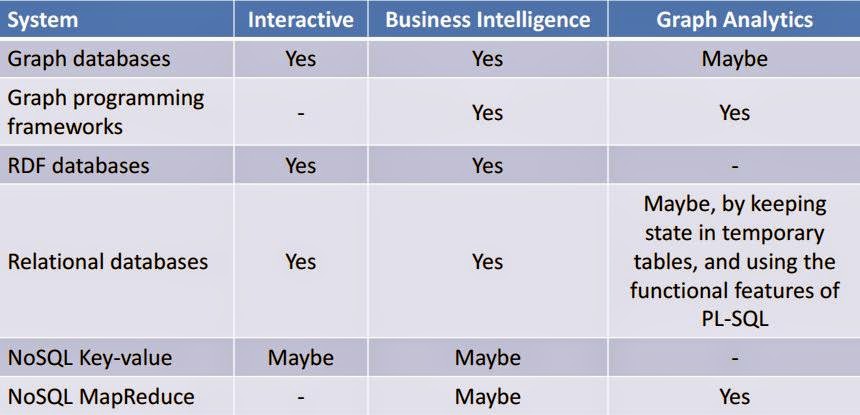
DATAGEN , SOCIAL NETWORK , SNBAs explained in a previous post, the LDBC Social Network Benchmark (LDBC-SNB) has the objective to provide a realistic yet challenging workload, consisting of a social network and a set of queries. Both have to be realistic, easy to understand and easy to generate. This post has the objective to discuss the main features of DATAGEN, the social network data generator provided by LDBC-SNB, which is an evolution of S3G2 [1].
One of the most …