Speeding Up LDBC SNB Datagen
Tags:
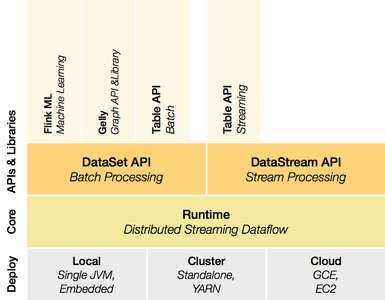
DATAGEN , SNBLDBC’s Social Network Benchmark [4] (LDBC SNB) is an industrial and academic initiative, formed by principal actors in the field of graph-like data management. Its goal is to define a framework where different graph-based technologies can be fairly tested and compared, that can drive the identification of systems’ bottlenecks and required functionalities, and can help researchers open new frontiers in high-performance graph data …