
Apache Flink [1] is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
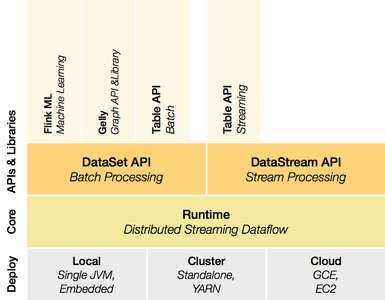
Flink offers multiple APIs to process data from various data sources (e.g. HDFS, HBase, Kafka and JDBC). The DataStream and DataSet APIs allow the user to apply general-purpose data operations, like map, reduce, groupBy and join, on streams and static data respectively. In addition, Flink provides libraries for machine learning (Flink ML), graph processing (Gelly) and SQL-like operations (Table). All APIs can be used together in a single Flink program which enables the definition of powerful analytical workflows and the implementation of distributed algorithms.
The following snippet shows how a wordcount program can be expressed in Flink using the DataSet API:
DataSet<String> text = env.fromElements(
"He who controls the past controls the future.",
"He who controls the present controls the past.");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter()) // splits the line and outputs (word,1)
tuples.groupBy(0) // group by word
.sum(1); // sum the 1's
wordCounts.print();
At the Leipzig University, we use Apache Flink as execution layer for our graph analytics platform Gradoop [2]. The LDBC datagen helps us to evaluate the scalability of our algorithms and operators in a distributed execution environment. To use the generated graph data in Flink, we wrote a tool that transforms the LDBC output files into Flink datasets for further processing [3]. Using the class LDBCToFlink, LDBC output files can be read directly from HDFS or from the local file system:
final ExecutionEnvironment env =
ExecutionEnvironment.getExecutionEnvironment();
final LDBCToFlink ldbcToFlink = new LDBCToFlink(
"hdfs:///ldbc_snb_datagen/social_network", // or "/path/to/social_network"
env);
DataSet<LDBCVertex> vertices = ldbcToFlink.getVertices();
DataSet<LDBCEdge> edges = ldbcToFlink.getEdges();
The tuple classes LDBCVertex and LDBCEdge hold the information generated by the LDBC datagen and are created directly from its output files. During the transformation process, globally unique vertex identifiers are created based on the LDBC identifier and the vertex class. When reading edge files, source and target vertex identifiers are computed in the same way to ensure consistent linking between vertices.
Each LDBCVertex instance contains:
- an identifier, which is unique among all vertices * a vertex label (e.g.
Person,Comment) * a key-value map of properties including also multivalued properties (e.g.Person.email)
Each LDBCEdge instance contains:
- an identifier, which is unique among all edges
- an edge label (e.g.
knows,likes) - a source vertex identifier
- a target vertex identifier
- a key-value map of properties
The resulting datasets can be used by the DataSet API and all libraries that are built on top of it (i.e. Flink ML, Gelly and Table). In the following example, we load the LDBC graph from HDFS, filter vertices with the label Person and edges with the label knows and use Gelly to compute the connected components of that subgraph. The full source code is available on GitHub [4].
final ExecutionEnvironment env =
ExecutionEnvironment.getExecutionEnvironment();
final LDBCToFlink ldbcToFlink = new LDBCToFlink(
"/home/s1ck/Devel/Java/ldbc_snb_datagen/social_network",
env);
// filter vertices with label “Person”
DataSet<LDBCVertex> ldbcVertices = ldbcToFlink.getVertices()
.filter(new VertexLabelFilter(LDBCConstants.VERTEX_CLASS_PERSON));
// filter edges with label “knows”
DataSet<LDBCEdge> ldbcEdges = ldbcToFlink.getEdges()
.filter(new EdgeLabelFilter(LDBCConstants.EDGE_CLASS_KNOWS));
// create Gelly vertices suitable for connected components
DataSet<Vertex<Long, Long>> vertices = ldbcVertices.map(new VertexInitializer());
// create Gelly edges suitable for connected components
DataSet<Edge<Long, NullValue>> edges = ldbcEdges.map(new EdgeInitializer());
// create Gelly graph
Graph<Long, Long, NullValue> g = Graph.fromDataSet(vertices, edges, env);
// run connected components on the subgraph for 10 iterations
DataSet<Vertex<Long, Long>> components =
g.run(new ConnectedComponents<Long, NullValue>(10));
// print the component id of the first 10 vertices
components.first(10).print();
The ldbc-flink-import tool is available on Github [3] and licensed under the GNU GPLv3. If you have any questions regarding the tool please feel free to contact me on GitHub. If you find bugs or have any ideas for improvements, please create an issue or a pull request.
If you want to learn more about Apache Flink, a good starting point is the main documentation [5] and if you have any question feel free to ask the official mailing lists. There is also a nice set of videos [6] available from the latest Flink Forward conference.
References
[2] https://github.com/dbs-leipzig/gradoop
[3] https://github.com/s1ck/ldbc-flink-import
[4] https://gist.github.com/s1ck/b33e6a4874c15c35cd16
[5] (link expired)
[6] https://www.youtube.com/channel/UCY8_lgiZLZErZPF47a2hXMA