LDBC and Apache Flink
Tags:
FLINK , DATAGEN , SNBApache Flink [1] is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
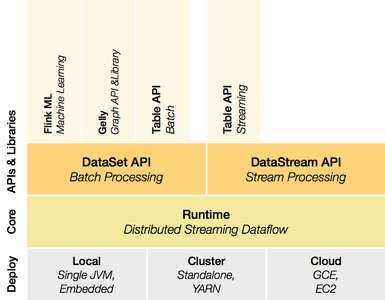
Flink offers multiple APIs to process data …