Introducing SNB Interactive, the LDBC Social Network Benchmark Online Workload
Tags:
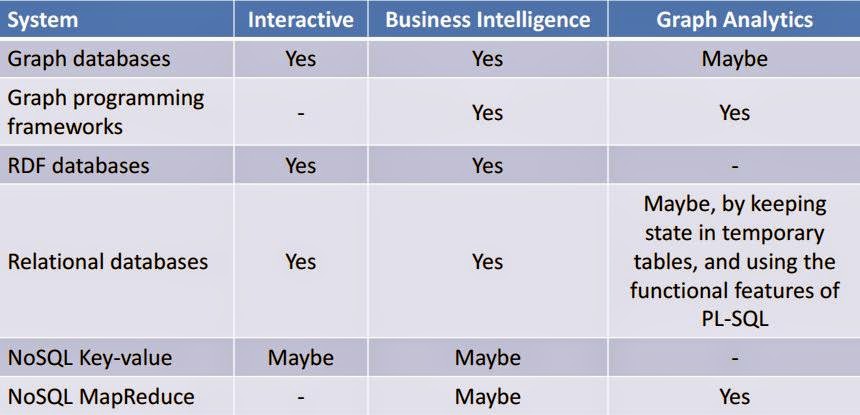
SNB , INTERACTIVEThe LDBC Social Network Benchmark (SNB) is composed of three distinct workloads, interactive, business intelligence and graph analytics. This post introduces the interactive workload.
The benchmark measures the speed of queries of medium complexity against a social network being constantly updated. The queries are scoped to a user’s social environment and potentially access data associated with the friends or a user and their friends.
This …